

LCA - Latent Class Analysis
Segmenting for success in both consumer and B2B markets means going beyond traditional segmenting variables, such as demographics or company type, and focusing on needs, attitudes and lifestyle.
[Erika Bruhn, Sawtooth Technologies Consulting]
As consumer diversity is increasing firms have sought to differentiate their products relative to both customers and competitors. Segmenting customers with similar needs and responses into groups provides a way of disaggregating markets into targets that can be served more profitably through advertising, positioning, placement and other generally oriented ways.
The most common segmentation bases are demographics (socioeconomic
characteristics, usage habits), psycho-graphics (personality, attitudes,
opinions, life style) and benefits sought, often obtained from MR. It is
known that the statements obtained from isolated questions presented to
respondents one by one often reflect self-perceptions of the individuals
rather than the attitudes influencing actual behavior. Differences in
evaluations of product features are smoothed out as nearly every aspect
becomes important when evaluated separately. Therefore a segmentation
based on direct questioning is often rather diffuse, and location of the
really important aspects is misty.
When a future behavior is concerned, people have tendency to give answers
they think they should give, often for the simple reason to be polite.
Bias in stated preferences to more expensive and higher quality products
compared to the reality is common .
An experimental type of interviewing carried out in the competitive context has proved to provide more reliable stated preferences and a sharper picture of the differences between various cognitive and perceptual aspects. This is supported by the observation that items chosen in a simulated experiment or simply from a selection of possible characteristics are often in disagreement with the hypothetical choices inferred from the statements about personal preferences derived from isolated questions asked in the same interview.
A typical experiment in a MR interview is realized as a number of choices
from selections. When the selections are made of representative products
or their profiles composed of attributes, the method is a variant of a CBC - Choice Based Conjoint
or SCE - Sequential
Choice Exercise method. When the selections are constructed as
batteries of pre-declared statements from which the respondent selects the
one or a small number of the most appropriate ones conditional to the
asked question, the choices will be from a multinomial distribution and
can be analyzed with the tools of log-lin analysis.
There is a general belief that simulated experiments will give a
better view of endogenous factors entering future markets than
predictions bases on historic data. This is attributed to the fact that
any market data are backward looking while data from a research experiment
are forward looking. Behavior of targets is changing with changing
experience, needs and expectations. With these ideas on mind we have added
LCA ? Latent Class Analysis of choice experiments to our portfolio of
market research methods.
As the simplest possible case, all the available data from a market research study can be separated into two basic sets. The first set X is made of the descriptive variables, called exogenous, that do not directly express the possible behavior of the individuals. The classical segmentation variables such as demographics belong to this set. The variables in the second set Y, called endogenous, are directly expressing the actual or expected behavior, or are indirectly bound to it in some way. This set is typically composed of subjective statements, choices from statement batteries, events (choices) on the real or simulated market, etc. While the number of variables in both groups can be quite high, only a limited number of marketing strategies, each for some behavioral segment of consumers, can be developed. The segments obtained with LCA are called latent classes that make the set L. There are two basic tasks to be done:
X ? L ? Y
In the actual estimation, the causal orderings, e.g. L ? Y, are replaced by the respective conditional probability densities, e.i. (Y|L). Not a fully exact but useful notion of the estimation process is a regression of the "dependent" variables from the set Y on the set L of latent variables and, at the same time, regression of the latent variables from the set L on the "independent" variables from the set X so that the total density (L|X)×(Y|L) is maximized.
The simplest type of analysis is solving for just the causal ordering L ? Y
for an unknown set L
of multinomial class variables. The solution is analogous to the dimension
reduction of a set of linear continuous variables. The important
difference is the levels of variables in the set L
represent discrete, mutually exclusive latent classes of individuals.
It is quite common to consider only one multinomial variable in the set L. Then the causal ordering X ? L can be solved as a multinomial regression of L on the variables from the set X . This procedure is known as segment profiling.
When both causal orderings in X ? L ? Y
are solved in one estimation step, the variables in the set X
are called concomitant variables. This approach is known as log-linear
path modeling for categorical variables, and is analogous to structural
equation modeling of linear continuous variables (LISREL). In our
experience this technique is worth of trying but fails when the set X is structurally
dominant and the set Y
diffuse which leads to trivial classes induced mostly by the set X.
In such a case the independent segment profiling is the preferred
procedure.
Conjoint analysis is one of the most efficient sources of behavioral data, namely in the forward-looking context. The set U of the profile utilities in the choice sets implicates the set C of choices. When the set Y in the latent class model L ? Y is replaced by the causal ordering U ? C , the model
L ? U ? C
is obtained. It is implemented in the commercial software CBC Latent Class Module of Sawtooth, Inc. As the software does not have capability to include concomitant variables only the successive segment profiling by multinomial regression can be used.
| LCA is based on maximization of the total probability of the observations over the subjects belonging to a distinct class. This distinguishes LCA from other clustering methods. |
|
The knowledge of membership of an individual to a behavior-based segment
can be an asset in efficient addressing him or her as a potential
decision maker (buyer, contributor, voter, etc.). If the future behavior
is embodied in historic data for individuals the latent classes can be
derived from such data. At the same time, exogenous variables can be used
as concomitant variables and make the identification more precise. In this
way the behavioral class membership can be predicted from readily
available data, e.g. from a client database. The typical use is in the
direct marketing. In case of a general marketing problem it is supposed
the segment profiling of the forward-looking data from a MR study should
be utilized.
Unfortunately, there is no universal method for finding the most appropriate set of latent classes and a way of assignment of an individual to the appropriate class. The problem is strongly "analyst dependent".
 As aside
As aside
The data of this example are those used in the MXD
- Maximum Difference Scaling example. Discrimination between
segments of potential users is quite stable. The segment of "Discount
seekers" in two-segment solution (36 %) has lost only 6 % in five-segment
solution. The composed segments of "Download seekers and photo hobbyists"
and "SW Users and security seekers" split very cleanly. The found
percentages might be useful for a refinement of the optimal
portfolio example based on the identical source data.
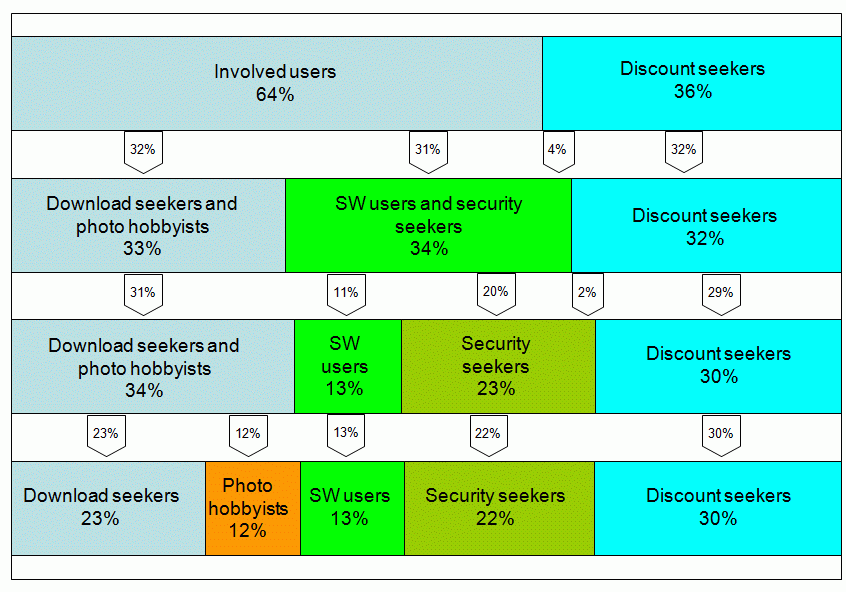
As aside
The data for this example come from a commercial CBC study of a
particular type of mobile telecommunication tariff benefits.
The segments in this example have mostly arisen from price sensitivities to the service rates and avidness for free benefits. As a surprising fact we had to accept an unexpectedly high number of SMS users who were distinctly more benefit sensitive than other users. Again, the segments are very stable in respect to the number of segments in the solution. We leave out the detailed explanation of the segment labels for apparent reasons.
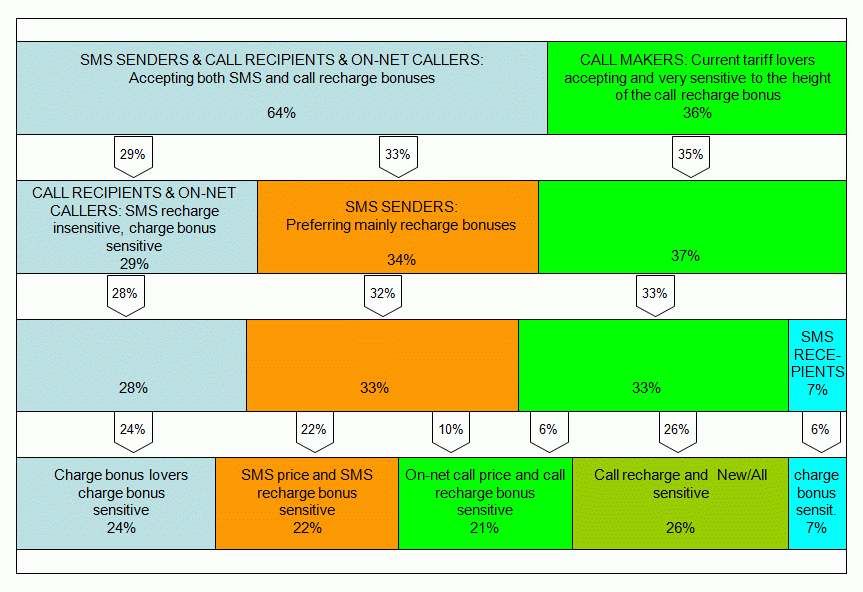
An additional tabular and/or graphic presentation of attribute
projections onto the identified consumer classes (a cross-tabulation, not
shown here) is a standard for a successful interpretation of the analysis.
Next to a (hopefully successful) segmentation the question arises who the
targets are and how to find them. For a targeted marketing effort it is
desirable to have means for prediction of the segment an individual
belongs to. As the segments are disjunctive a suitable tool may be based
on multinomial regression of the segments on some available data on the
individuals. The data may typically reflect attitudes, perceptions, usage,
previous actions, demographics etc. This technique is known as segment
profiling.
| It is very hard to predict prior the
study if the analysis will give usable results. The success or
failure depends on the relevancy of the data in the available
database. In our experience, the results lie between the two
extremes. |
|
In practice, the results lie in between the extremes. The analysis can tell which variables are useful, which are not and might be omitted, and which additional variables, if available in the study, should be added to the standard collection.
A financial institution decided to introduce new leaflet formats for
informing regular clients about new products. With SCE
- Sequential Choice Exercise as the interviewing procedure and LCA
by LEM from LEM
software as the analytical method, we ascertained the most promising
leaflet formats for three identifiable classes of clients making about 60%
of the total. The identification could be made on 4 readily available
variables. The average likelihood of the generalized statement based on
"would read it", "would be interested in", etc., was two to three times
higher compared to sending leaflets in a format selected randomly.
While LCA is most often used to classify targets it can be also used to classify items such as brands, companies, locations, etc. Usage and attitude studies often rely on discrete single (radio button) or multiple (check-box) response based questionsorganized into batteries. The answers are direct candidates for a DCM-based analysis. Data from Likert scale questions can be used "as is", i.e. as linear level values, or, preferably, transformed to a discrete choice format using the rank-explosion rule.The inherent non-linearity of the scale is thus avoided.
Vector based perceptual mapping systems such as Sawtooth Software CPM (Composite Product Mapping) use projection of perceptions on vector components. Usually two components are used so that the complex relationships can be distilled into a single two-dimensional picture (a perceptual map) that conveys the insights. In contrast, LCA produces several classes that have indeterminate orientation in the space. LCA searches for the differences between groups of the items rather than between individual items. As a rule of thumb, a product belongs mostly to a single class, and only rarely to more than two neighboring classes. The classes can be taken for vectors, and the items visualized in a single picture by averaging their probabilities of membership in the classes.
Five classes of potato chips (crisps) were identified as optimal. The size of bubbles is only half of the actual overlay size of the classification (the full size of the bubbles would make the picture unclear). Position of a brand can reach at most the circle encompassing the ends of the coordinates (not shown) that represent the "clean" classes and can be understood as class archetypes. In this particular case, no brand of chips is commonly perceived as being for young or wise, or having an image of unmatched quality. The perceptions are uniquely personal and user dependent, but on average, most of the brands are perceived as "simply chips at a leisure time".

The classification has been done using 7 perception batteries. Projection
of the perceptions into the classes can give a picture of the perception
associations related to the classes. Projections of one of the batteries
onto the five extracted classes is in the picture below.

It is clearly seen that the terms "innovative" or "matchless" do not add to discrimination
between the product classes.
As aside