

SCE - Sequential Choice Exercise
Concept testing with concepts presented randomly and evaluated one by one is little efficient. Frequent ties and inconsistencies in evaluation are the major disadvantages. Evaluations often show a drift to lower acceptances and to a lower discrimination between the concepts offered later. Reliability of answers is decreased as fatigue and annoyance of respondents from the interviewing is increasing.
A remedy was searched in various flavors of concept sorting. "Sort conjoint" based on ranking of concepts was popular some decades ago. Q-Sort method is experiencing a renaissance. While efficiency could be improved some problems appeared.
When sorting a number of items in place respondents tend to give more weight to general benefits and advantages they see rather than to their personal needs, expectations, affordability or other personal values. When the items are permanently visible during the sorting the respondent may get impression that the final decision of the actual choice can be made later.
The method was inspired by the VCT - Virtual Concept Test [Dahan, E., and Hauser, J.R. (2002). The Virtual Customer. Journal of Product Innovation Management, 19, 332-353]. VCT is experimentally a sequential choice method without replacement and, therefore, does not suffer from the drawbacks inherent to in-place sorting. Such an arrangement allows to achieve an "out of sight, out of mind" state for previous choices from the set, and makes the choices more realistic.
In SCE, the original monotonous OLS estimation method of ranks has been replaced with hierarchical Bayesian estimation of part-worth from a number of custom generated choice sets.
 As aside
As aside
A number of consecutive choices from a set can provide more information in lesser time and effort compared to a number of single choices from randomized choice sets. It is known that ranking of low priority items is generally subject to gross error. It is often possible to break the ranking process at some point or to limit the maximal number of sequential choices without an excessive loss of information.
The prospect of a gradually simplified task prods a respondent to more reasonable decisions and statements. Each of the following choices takes less time since the decision maker has already come down to an opinion about the items remaining in the choice set. The influence of the previous choices is decreased since they are not visible anymore and are (at least partially) forgotten. The interviewing time and the exercise-induced fatigue of respondents is substantially lowered which contributes to higher reliability of the data.
As aside
The main results of SCE analysis are part-worths of the items and can enter what-if simulations of the share type. If calibrated to become item utilities, they can be used in estimation of stated acceptance and competitive potential of the concepts.
A natural next step in interpretation of the results is search for the best subset of the tested concepts that would gain the highest reach using DCM Portfolio Optimization method. Additional information can be obtained from grouping interviewed subjects according to the appeal the concepts have on them using LCA - Latent Class Analysis.A unique advantage of SCE lies in its general DCM principle allowing to combine SCE data with data from other types of discrete choice, such as CBC, MaxDiff, single or multiple-choice batteries (of the type "select any that apply"), best-worst choice exercises, etc.
The only but crucial disadvantage of SCE is a limited number of items that can be ranked. As in any sorting method, this is due to the requirement a respondent must read and remember all the tested items before having made the first choice. When items are very complicated (such as banking, insurance, etc. products) SCE is appropriate to only a few profiles. The limit for statements not exceeding about 15 words (say a short line) is about 15 items. Good results have been obtained for 20 items each described by 4 words at most.
As aside
If the number of items is too high to be tested in a single SCE exercise,
subsets of concepts can be generated from the master set. In a computer
controlled interview, every respondent can be presented a different
orthogonal and balanced subset of items. Alternatively, a preliminary
piling of items into groups suggested in Q-Sort method can be used, and
the piles or their subset are amenable to SCE exercises.
The low number of concepts the SCE exercise allows may be prohibitive if relatively subtle differences in concepts are of importance. In such a case either CBC - Choice Based Conjoint or MaxDiff - Maximum Difference Scaling should be the preferred method. In contrast to SCE, these methods require much simpler descriptions of concepts as each concept has to be shown to and evaluated by a respondent many more times.
Q-Sort method is a typical example of a method leading to ranks with ties. The same is true for batteries of evaluation questions on a Likert scale when converted to ranks. The current methods of data transformation to be used in DCM rely on specially constructed likelihood terms to be maximized. The principle is a merger of two or more tied choices in the same choice set. Unfortunately, the method is not available in commercial estimation programs.
Using the choice set generation method developed for SCE, account of tied ranks can be taken by omitting the choice sets containing tied items of which any item has been chosen. As the set of choice sets is near-to-orthogonal the loss of information is proportional to the number of tied choices in the data. In this way the actual data weight for the respondent is reflected. This approach allows for DCM-based processing of data from Likert scale batteries (see an example below) or Q-Sort exercises, and merging them with genuine choice-based data such as CBC, MaxDiff, MBC, SCE, etc.
As aside
The usual steps in an SCE - Sequential Choice Exercise are as follows.
The original purpose of a standalone SCE was an estimation of a competitive potential of products or services in presence of competing products, typically in a pre-launch study. The discrimination power appears to be clearly better than from evaluation of concepts shown by random. The improvement is comparable to that of a switch from a standard battery-based evaluation of items to the MaxDiff - Maximum Difference Scaling method.
If the items to be sorted are product concepts, they should be of a managerial type. They should reflect the expected demand and utilize the known trade-offs of the product attributes, typically performance and quality vs. price. The concepts should be provided by the producer or vendor with the advantage of skintight knowledge and expertise a research agency seldom has. Each concept that enters the test is considered an independent entity with its own utility. In contrast to a conjoint study, there are no limitations imposed on the properties (attributes and their values) of the concepts.
SCE is a very general concept and method. It can be deployed anywhere a ranking is desirable. It has proved to be an alternative to MaxDiff in case the number of tested items is small, or the items are complicated, i.e. not easily comprehended, assessed and evaluated in a brief (and superficial) judgment.
| SCE of concepts is of advantage in the following cases: |
|
| Typical use of SCE is in the following tasks: |
|
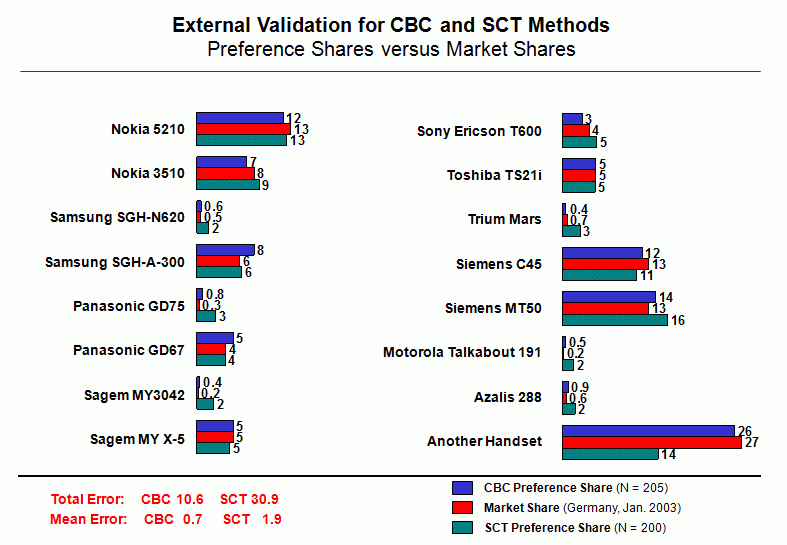
The comparison led to a conclusion that SCT gave a worse agreement with the market and higher error than CBC. In addition, respondents claimed higher annoyance and a temptation to prematurely finish the interview with SCT. This could be attributed to the request for making all possible 15 choices. From today's view and knowledge, 5 to 8 choices would do. However, there were still only 16 product profiles shown to each respondent in SCT compared to 105 product profiles in CBC.
SCE is particularly useful for testing (a relatively low number of) complicated and hard to evaluate profiles rather than for simple brand-price ones where CBC is no doubt the preferred method.
A full-fledged statistical verification of the SCE method would require a subsidized study. To present a visual proof, SCE data were simulated from the results of a MaxDiff study on importance of 36 items related to a banking service. Every respondent from a sample of 870 made the best choices from 14 randomized sets by 5 items. SCE data were obtained by simply sorting the obtained importance part-worths. The first 18 simulated choices were used in the SCE estimation. Items are labeled as B01 to B36 by decreasing aggregated influence obtained from the MaxDiff study. The influences were computed as choice likelihoods from the full set of items, i.e. they sum to 100%.


The results for SCE are similar to those for MaxDiff with the first reversal for item B15. This may be due to non-existent (i.e. zero) within-respondent covariances between items for rankings. For the same reason the scaling factor (steepness) of the estimated part-worth is slightly higher than in MaxDiff. These differences should have no detrimental effect on interpretation of results in practice.
Since an SCE experiment is easily implemented, a simpler method than building a special design and use of hierarchical Bayes estimation has been searched for. Based on "look & feel" of typical results from MaxDiff and some theoretical assumptions, a simple finite computational procedure has been developed. Results for reduced numbers of sequential choices simulated from the above MaxDiff are in the picture below.


The simplified computation procedure with only 6 (simulated) choices from 36 items seems to give a quite satisfying result.
Direct ranking in a questionnaire can be used only for sets with a limited number of items. With many tens of items, battery of questions asking to evaluate items on a Likert scale is more appropriate. A DCM approach with hierarchical Bayes estimation can improve results and their interpretation.
An employee attitude study for 1000 respondents was composed as a battery of 60 items organized in 8 blocks. Both the blocks and items in each block were randomized to compensate for possible drifts in answers. The symmetrical Likert scale had 6 levels from 1 - strongly disagree to 6 - strongly agree. Respondents have largely used the positive side of the scale.
So that the direct answers could be compared with an SCE tied rank approach, the stated values were decreased by a "neutral level" value 3.5 common to all respondents, and then averaged over the sample. The resulting pattern should be similar to perception values used e.g. in OBIMA method. The required reference "zero" item (a threshold) common to all respondents was assigned a formal rank that was preferred over the Likert level 3, and the Likert level 4 was preferred over the reference. The results are shown below.


Patterns of aggregated results from both methods of analysis are nearly identical with no significant systematic bias in SCE. Some differences can be attributed to different definitions of reference items, i.e a fixed value (the third one) in a Likert scale and an estimated threshold value (zero part-worth) in SCE approach. While Likert values are arbitrary and have no direct interpretation, estimated SCE perceptions are closely related to the number of respondents who either agree or disagree with the statement.
As aside
Data from large Likert-scale batteries are often subject to a clustering. In this case, as it is in many other cases of direct clustering based on the answered values, respondents were categorized according to the interval of values they were selecting from. E.g., a 3 group solution consisted of groups of respondents selecting either mostly low, or medium, or high Likert values. Clustering based on relative values obtained by centering the answers for each respondent lead to apparently reasonable groups, however, the partitioning of groups was not sufficiently clean. A new group in (K+1) group solution was too often created by taking respondents from several groups of K group solution. In contrast, SCE offers a possibility to base clustering on probability values in a way similar to LCA - Latent Class Analysis known for clean partitioning. Use of hierarchical Bayes estimation can correct outliers or ties by sweeping them closer to the sample means thus facilitating the clustering process. The result of clustering 977 respondents (23 gave identical answer for all 60 evaluated items) based on relative perceptions (rather than on absolute perceptions shown above) is in the picture below.

It is important to remember the groups are based on relative rather than absolute evaluation of items, i.e. the differences between the evaluation levels selected by each respondent. An interesting finding is that all those happy with their job are critical to management and see future prospects for themselves even when they consider their current job dull. On the other hand, those dissatisfied and disillusioned do not see future prospects of their personal growth irrespective of working climate or management evaluation.